Abstract
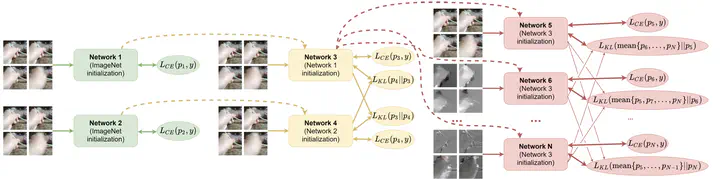
The construction of models for video action classification progresses rapidly. However, the performance of those models can still be easily improved by ensembling with the same models trained on different modalities (e.g. Optical flow). Unfortunately, it is computationally expensive to use several modalities during inference. Recent works examine the ways to integrate advantages of multi-modality into a single RGB-model. Yet, there is still room for improvement. In this paper, we explore various methods to embed the ensemble power into a single model. We show that proper initialization, as well as mutual modality learning, enhances single-modality models. As a result, we achieve state-of-the-art results in the Something-Something-v2 benchmark.
Aleksandr Petiushko Александр Петюшко
Director, Head of ML Research / Adjunct Professor / PhD
Principal R&D Researcher (15+ years of experience), R&D Technical Leader (10+ years of experience), and R&D Manager (7+ years of experience). Running and managing industrial research and academic collaboration (35+ publications, 30+ patents). Inspired by theoretical computer science and how it changes the world.