CC-Cert: A Probabilistic Approach to Certify General Robustness of Neural Networks
Abstract
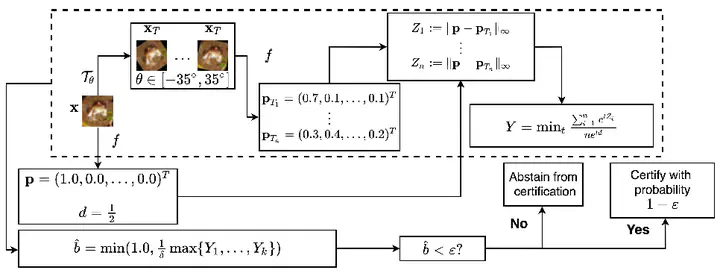
In safety-critical machine learning applications, it is crucial to defend models against adversarial attacks — small modifications of the input that change the predictions. Besides rigorously studied $\ell_p$-bounded additive perturbations, semantic perturbations (e.g. rotation, translation) raise a serious concern on deploying ML systems in real-world. Therefore, it is important to provide provable guarantees for deep learning models against semantically meaningful input transformations. In this paper, we propose a new universal probabilistic certification approach based on Chernoff-Cramer bounds that can be used in general attack settings. We estimate the probability of a model to fail if the attack is sampled from a certain distribution. Our theoretical findings are supported by experimental results on different datasets.
Aleksandr Petiushko Александр Петюшко
Head of AI / Vice President, Head of RnD / Adjunct Professor / PhD
Principal R&D Researcher (20 years of experience), R&D Technical Leader (15 years of experience), and R&D Manager (10 years of experience). Running and managing industrial research and academic collaboration (45 publications, 40 patents). Hiring and transforming AI/ML teams. Inspired by theoretical computer science and how it changes the world.